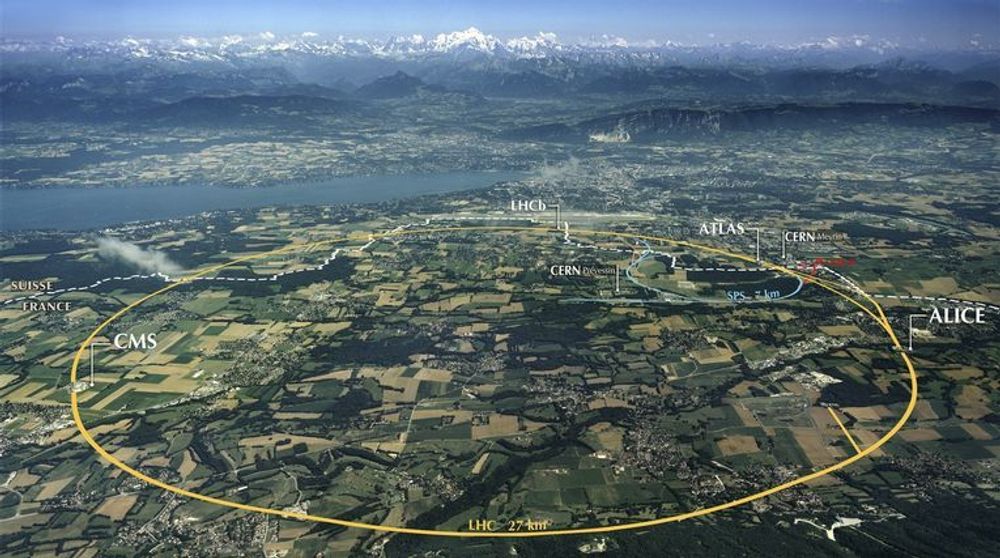
I partikkelakseleratoren (kalt LHC for «Large Hadron Collider) til den europeiske organisasjonen for kjernefysisk forskning (CERN), verdens største, foregår det fire store eksperimenter. Et av disse er LHCb der b står for «b-hadron», også kjent som «beauty quark».
Eksperimentet består i å samle opp data som fanges opp av sensorer langs hele den ringformede 27 kilometerlange underjordiske akseleratoren, der partikler kolliderer med hverandre. Hvert år genereres tusener av terabyte med data. Selve forskningen består i å studere disse dataene i jakt på ny viten om grunnleggende fysiske lover, med håp om innsikt i hvordan verden ble til.

Dataene samles fortløpende. LHCb-eksperimentet sysselsetter 700 fysikere på heltid. De studerer 20 milliarder partikkelkollisjoner i året. Dataene analyseres sekvensielt for å sile ut bestemte typer begivenheter. Dataene er spredd på store serverfarmer, og det tar flere timer å få ut det man er ute etter.

Den åpenbare løsningen på en slik utfordring er å tilpasse søketeknologi slik at man kan spesifisere karakteristikkene til begivenhetene man er interessert i, og la dataene siles automatisk av en søkemotor.
10. april i år kunngjorde russiske Yandex at de, i samarbeid med CERN, har utviklet søketeknologi spesielt tilpasset LHCb-eksperimentet. Yandex driver Russlands største søketjeneste, der de har 60 prosent av hjemmemarkedet, mot 28 prosent for Google. Selskapet ble verdsatt til 7 milliarder dollar da de debuterte på Nasdaq-børsen i New York i mai i fjor.
Ifølge Business Week kom samarbeidet mellom Yandex og CERN som følge av en henvendelse til Yandex fra en av de russiske forskerne som er med på LHCb, Andrei Golutvin. Yandex stilte med fem utviklere, alle med bakgrunn fra kjernefysisk forskning. Utviklingen av den LHCb-spesifikke søketeknologien tok tre måneder. Yandex har også stilt serverkapasitet til disposisjon for LHCb, anslagsvis 13 prosent av eksperimentets behov. Yandex har ikke tatt seg betalt for noe av dette.
Hittil er data tilsvarende rundt én milliard partikkelkollisjoner indeksert – tilsvarende 5 prosent av det LHCb produserer av data i løpet av et år – og gjort søkbar etter 600 kriterier. Målet er å indeksere alle LHCb-data og deretter holde tritt med eksperimentets daglige produksjon.
Talspersonen for LHCb, Pierluigi Campana, er svært begeistret. Silingsarbeidet som tidligere tok mange timer, kan nå gjøres unna på sekunder.
– Dette søkesystemet er tilrettelagt for våre behov. Det sparer oss for tid og ressurser, og det vil bety mye for forskningen vår, sier han.
Yandex har ikke tatt stilling til hvorvidt de skal følge opp søketeknologien for LHCb med tilsvarende løsninger for andre eksperimenter.
IT-professor Ram Akella sier til Business Week at det er et åpenbart behov innen mange forskningsgrener, som genforskning og biomedisin, for tilrettelagt søketeknologi. Markedet ligger åpent for den som vil engasjere seg. Google har ikke kommet spesielt langt: De har hittil nøyd seg med verktøyet Fusion Tables som forenkler arbeidet med å samle, dele og analysere data, og med å gi utvalgte forskere tilgang til serverressurser.
Yandex har hittil ikke gjort spesielt mye for å skaffe blest rundt sitt bidrag til CERN, utenom selve pressemeldingen.
