
Microsoft mener det er store muligheter knyttet til bruken av dyp læring i forbindelse med detektering og klassifisering av skadevare. Allerede er dette til en viss grad tatt i bruk i selskapets Threat Protection-produkt. Samtidig har forskere hos Microsoft Threat Protection Intelligence Team and Intel Labs samarbeidet om videre utforskning av nye teknikker.

Sikkerhetsselskap med nye, alarmerende funn
Datasyn og dyp overføringslæring
Ett av de områdene som forskerne har sett på, er å utnytte teknikker innen datasyn («computer vision») til klassifisering av skadevare, ved å gjøre om skadevare til bildepiksler.
Datasyn handler om hvordan datamaskiner kan forstå innholdet i digitale bilder og videoer. Dette er et område innen dyp læring der det har blitt gjort mange framskritt de siste årene, så det gir mening å låne kunnskap og metoder fra dette feltet til nye formål, inkludert det å finne mer skalerbare metoder for analyse av skadevare.
I det aktuelle tilfellet har forskerne tatt i bruk en teknikk som kalles for dyp overføringslæring («deep transfer learning»). Dette dreier seg om å overføre hele eller deler av kunnskapen et nevralt nettverk har oppnådd under trening, for eksempel på å gjenkjenne katter i bilder, til bedre å gjøre en annen, lignende oppgave, for eksempel å utføre diagnoser basert på røntgenbilder.
AI-eksperten Andrew Ng forklarer konseptet i videoen nedenfor.
Statisk analyse
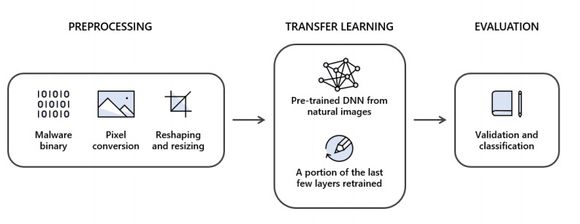
Forskerne har kalt tilnærmingen sin for STAMINA (static malware-as-image network analysis). Ved statisk klassifisering brukes kun egenskaper ved programvarefilene som kan observeres uten at filene kjøres.
STAMINA har vist seg å kunne gjenkjenne skadevare med svært høy nøyaktighet og en lav andel av falske positive svar i et forsøk hvor det er brukt et utvalg med blant annet hasher hentet fra 2,2 millioner skadevareinfiserte binærfiler. 60 prosent av binærfilene i utvalget ble brukt til trening. 20 prosent ble brukt til validering, mens de resterende 20 prosent ble brukt til testing.

Hjerneimplantat overførte tanker til tale – nesten i sanntid
Gjøres om til JPEG-bilder
Med STAMINA gjøres skadevarefilene altså om til bildedata. I praksis gjøres de først om til en endimensjonal, gråtone-pikselstrøm hvor hvert byte i den kjørbare filen gis en verdi på mellom 0 og 255, som korresponderer med pikselintensiteten. Deretter blir pikselstrømmen gjort om til et todimensjonalt JPEG-bilde. Høyden og bredden på bildet bestemmes ut fra størrelsen på binærfilen.
Det skal også være mulig å endre størrelsen på bildet uten at dette påvirker klassifiseringsresultatet på noen negativ måte. Dette forklares av forskerne med at systemet som de bruker, trener et veldig dypt, nevralt nettverk for å hente ut de dypt representerte egenskapene.
Både styrker og svakheter
Metoden var i stand til å identifisere og klassifisere skadevaren med en nøyaktighet på 99,07 prosent med en rate for falske positiver på 2,58 prosent, et resultat forskerne ble oppmuntret av.
STAMINA-metoden har likevel noen svakheter. Blant annet egner den seg best i forbindelse med relativt små filer. Metoden blir mindre effektiv dersom filene må konverteres til milliarder av piksler, som settes sammen til et JPEG-bilde, som deretter krympes. I slike tilfeller er det fordeler ved å bruke metadata-baserte metoder i stedet.
En vitenskapelig rapport om forskningen er tilgjengelig her.

Windows 10 er fortsatt sårbar


