Talegjenkjenning begynner å fungere ganske bra, men hvis det er mange samtidige stemmer eller mye bakgrunnsstøy sliter datamaskinene ofte med å isolere stemmen til én bestemt person. Dette er noe mennesker klarer veldig godt takket være det som kalles «coctail party-effekten», hvor menneskehjernen automatisk kan fokusere på det én person sier og mentalt «koble ut» alle andre stemmer i rommet.
Nå har Google ved hjelp av maskinlæring klart å utvikle en teknologi som gir datamaskiner de samme mulighetene. Det skriver Google i et blogginnlegg, som blant andre Arstechnica viser til.
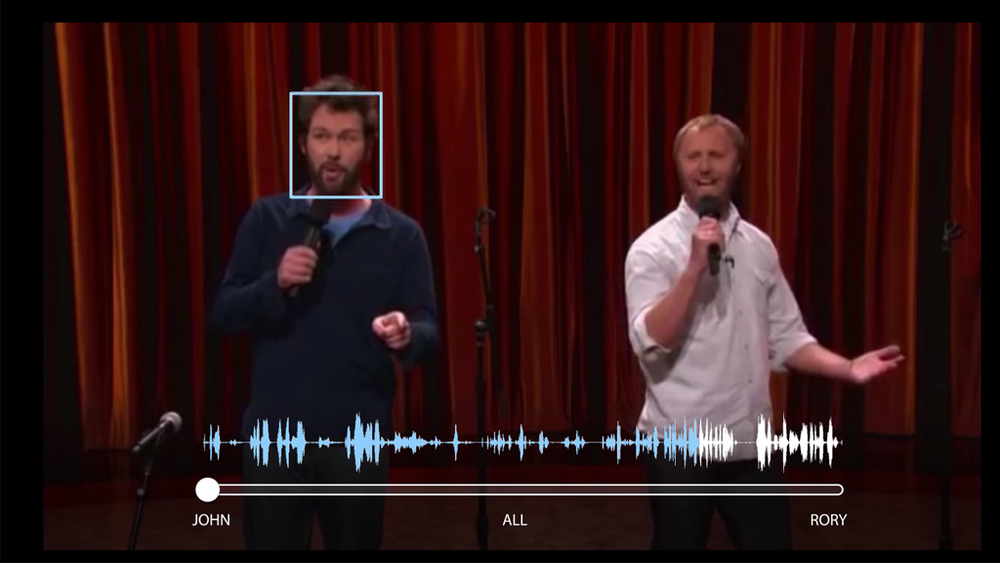
Google bruker en audio-visuell modell som fungerer på vanlige videoer med ett enkelt lydspor. Brukeren kan velge ansiktet til den personen de vil høre, eller datamaskinen kan velge personen automatisk basert på kontekst. Da vil stemmen til den valgte personen forsterkes, mens all annen lyd dempes.
Kan forbedre talegjenkjenning eller gi bedre høreapparater
Google ser for seg en rekke mulige bruksområder for teknologien. Det kan for eksempel være å gjøre tale i video tydeligere, eller gi bedre talegjenkjenning fra videoer. Eller det kan være forbedrede videokonferansesystemer eller hjelpemidler for hørselshemmede, spesielt i tilfeller der det er mange mennesker som snakker. Automatisk teksting er et annet bruksområde.
Løsningen er avhengig av både lyd og video for å separere tale, og kan isolere stemmer blant annet ved å se om bevegelser av munnen til de som snakker korresponderer med hva som blir sagt. Som det fremgår av illustrasjonen nedenfor er det først ett lydspor som vil bli splittet i flere – ett for hver person i videoen som snakker.
Forskerne begynte med en samling av 100.000 videoer i høy kvalitet fra Youtube, blant annet undervisningsvideoer og taler. Ut fra dette klarte de å hente ut rundt 2000 timer med videomateriale hvor personer er synlige for kameraet og snakker uten bakgrunnsforstyrrelser. Dette ble så igjen brukt til å generere «kunstige coctail-partyer», en blanding av videoer av ansikter og tilhørende stemmer, mikset med bakgrunnsstøy.
Disse dataene ble så igjen brukt til å trene en maskinlæringsmodell til å splitte opp de ulike stemmene for hvert ansikt i videoen til separate lydstrømmer. Du kan lese flere detaljer om hvordan det fungerer i forskningsrapporten.
Her kan du se en demonstrasjon av hvordan det kan fungere:




