På superdatamaskintreffet Supercomputing 2009 i Portland i delstaten Oregon har IBM lagt fram de nyeste resultatene fra et langsiktig prosjekt for kognitiv databehandling. Prosjektet tar sikte på å bygge en ny modell for databehandling, ved å finne ut av hvordan hjerner i pattedyr fungerer, og lage elektronikk som fungerer på samme måte.
Dagens modell for databehandling skiller strengt mellom program – beregninger – og data, og data i minne skrives stadig over, mens programmene bevares. Ting skjer svært raskt, men få prosesser kjøres samtidig.
Kognitiv databehandling dreier seg om å bruke store antall av replikerbare enheter, tilsvarende nevroner og synapser (hjerneceller og de «lærende» koplingene mellom dem), der det ikke er noe klart skille mellom data og program, og der minne ikke overskrives.
I hjernen skjer informasjonsbehandlingen parallelt og distribuert, i områder spesialisert på bestemte oppgaver, med en høy grad av rekonfigurasjon og feiltoleranse. Man lærer av erfaring, og innholdet i minne bygges opp etter hvert som man lever. Hver enkelt operasjon tar lang tid sammenliknet med klokkefrekvensen i moderne prosessorer, men massivt parallell informasjonsbehandling gjør at mennesker og dyr kan reagere svært raskt. Greier man å gjøre noe tilsvarende med elektronikk, vil resultatet bli svært effektiv og rask behandling av store mengder digitale data, og en evne til å oppdage mønstre, lære av erfaring og anvise handlinger som er høyt hevet over dagens modell.
IBM mener denne modellen er påkrevet for framtidens databehandling, der det nettopp er behov for samtidig behandling av enorme mengder data, for raskt å kunne ta beslutninger basert på tidligere erfaring og tilpasset miljøet man opererer i.
Med andre ord: Skal forretningslivet spesielt, og moderne samfunn generelt, kunne fungerer effektivt og rasjonelt, er det påkrevet med kognitiv databehandling. Kognitiv databehandling er vilkåret for beslutningsstøtte som virkelig kan avdekke mønstre i mengder av digitale data, og ta kjappe og korrekte avgjørelser. «Business intelligence» vil fornyes totalt..
– Det er påkrevet at vi lager mer intelligente datasystemer som hjelper oss til å finne mening i den stadig økende mengden av [digital] informasjon, på samme måten som våre hjerner kjapt kan tolke og handle i kompliserte gjøremål, sier Josephine Cheng, direktør ved IBM-laboratoriet Almaden.
En viktig utfordring er at elektronikk for kognitiv databehandling må gjenta hjernens ytre egenskaper: lav fysisk volum og lavt energiforbruk. IBM har tro på at nanoteknologi og pågående forskning innen faseskiftminne og magnetiske tunneloverganger skal utfylle framskrittene innen simulering og algoritmer.
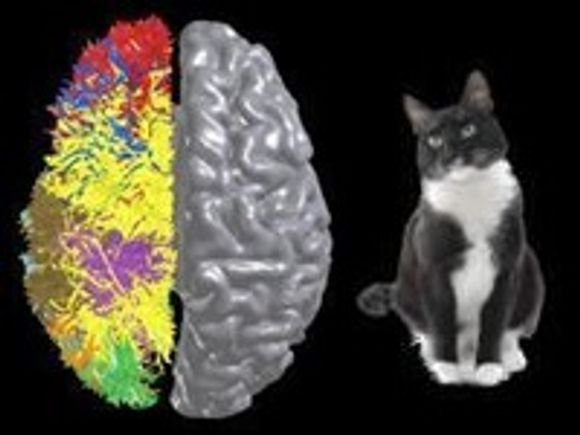
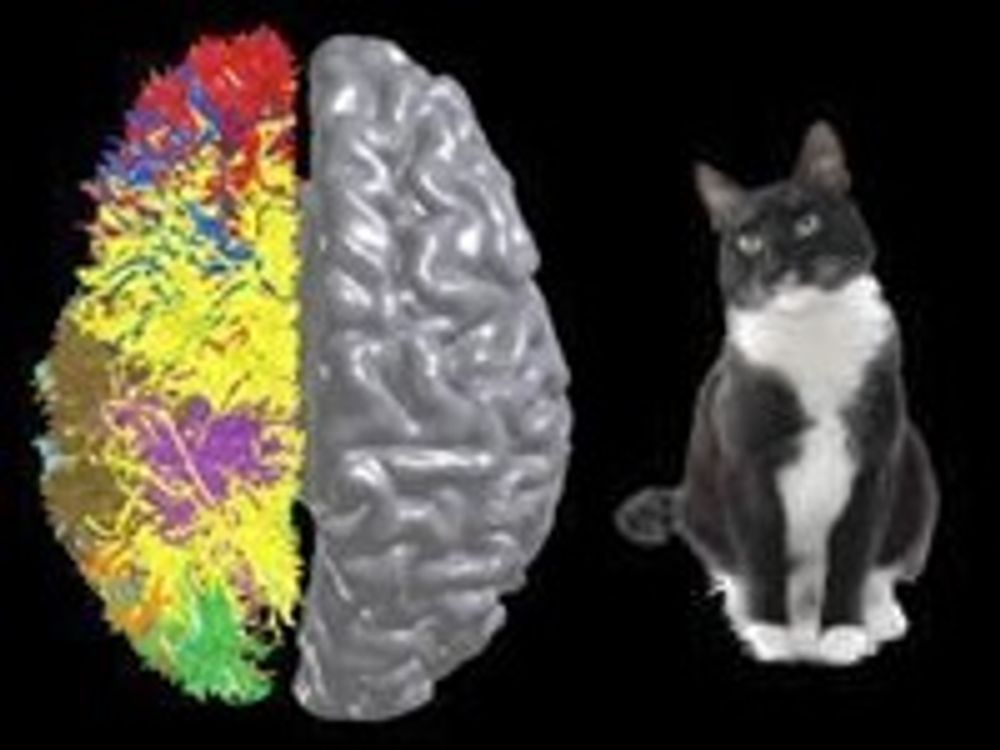
I Portland ble det lagt fram to viktige nyheter fra denne forskningen, som begge betraktes som store framskritt: En algoritme for å måle og kartlegge forbindelsene mellom hjernebarken og den underliggende hjernemassen, og en ny hjernebarksimulering tilsvarende hjernebarken på en katt.
Den nye algoritmen, «BlueMatter», kjører på IBMs supermaskinarkitektur Blue Gene. Inndata er bilder hentet gjennom skanninger etter metoden med magnetisk resonans.

Hjernebarksimuleringen beskrives som et programvareinstrument for å teste hypoteser om hjernenes struktur, dynamikk og funksjon. Den kjøres også på supermaskiner av typen Blue Gene/P.
Hjernebarksimuleringene til IBMs prosjekt for kognitiv databehandling har pågått i mange år. Hver fase er oppkalt etter dyret der hjernen kommer nærmest den som simuleres. I desember 2006 kunne man simulere 40 prosent av hjernen på en mus. Maskinen hadde 4 096 prosessorer og 1 terabyte minne, og simulerte en hjerne på 8 millioner nevroner og 50 milliarder synapser. Simuleringen skjedde i trinn på én millisekund, og det tok 10 millisekunder å simulere hver millisekund.
I april 2007 nådde prosjektet fram til rottestadiet, på en Blue Gene/P med 32 768 prosessorer og 8 terabyte minne. Den simulerte hjernen besto av 56 millioner nevroner og 448 milliarder synapser. Det tok fortsatt 10 millisekunder å simulere én millisekund.
I mars i år kom et stort gjennombrudd. På en annen Blue Gene/P, med samme antall prosessorer, men med 32 terabyte minne, nådde man opp til 1 prosent av menneskehjernen: 200 millioner nevroner og 2000 milliarder synapser. Simuleringen skjedde i trinn på 0,1 millisekund, og det tok 83 millisekunder å simulere én millisekund.
Den nyeste simuleringen er på høyde med hjernebarken til en katt.
Den kjøres på Blue Gene/P-maskinen til Lawrence Livermore-laboratoriet, med 147 456 prosessorer og 144 terabyte minne. Den omfatter en milliard nevroner og 10 000 milliarder synapser. Modellen er kraftig utvidet i forhold til simuleringen i mars i år. På den andre siden går simuleringen fortsatt i trinn på 0,1 millisekunder, og det tar stadig 10 til 100 millisekunder å simulere én millisekund. Forskerne karakteriserer dette som «tilnærmet sanntid». Den simulerte hjernen tilsvarer 4,5 prosent av menneskehjernen.
På sin blogg forklarer en av forskerne i prosjektet, Dharmendra S. Modha, at de regner med å kunne nå fram til en simulering av menneskehjernen i løpet av 2019. Resonnementet bygger på en ekstrapolasjon av simuleringene hittil, vurderte ut fra framskrittene innen supermaskiner siden tidlig på 1990-tallet.
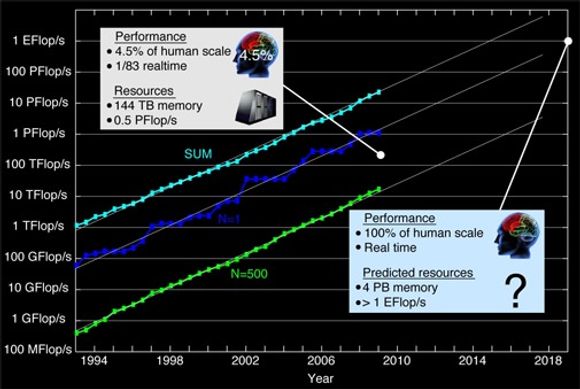
Den mørkeblå grafen viser den kraftigste maskinen på Top500-listen. Den lyseblå er den samlede ytelsen til alle på listen, og den grønne er ytelsen til den siste på listen. Merk at ytelsesskalaen er logaritmisk, slik at den eksponentielle utviklingen – som er i samsvar med Moores lov – vises som en rett linje. Maskinen som kreves for å simulere menneskehjernen – 4 petabyte med minne og over en exaflop/s i ytelse – kan være tilgjengelig for forskerne fra 2019.


Skal drømmen om kognitiv databehandling i menneskeskala realiseres, må det også skje grunnleggende framskritt innen elektronikken. Blue Gene/P med over 145 000 prosessorer er ingen erstatning for en virkelig katt, som ikke bare er 83 ganger så rask, men også langt mer kompakt og mye mer energieffektiv.
Forskningsrapportene for både katteskalasimuleringen og BlueMatter-algoritmen kan lastes ned fra Modhas blogg, se lenken ovenfor.
Les også:
- [08.08.2014] Denne prosessoren skal etterligne hjernen
- [15.11.2012] Nå simulerer den menneskehjertet
- [27.10.2011] Håper å simulere menneskehjernen innen 2019
- [19.08.2011] IBM viser prototyp på ny type prosessor
- [04.12.2009] IT-forskningen i Oslo er Nordens beste
- [29.10.2009] Nytt gjennombrudd for nestegenerasjon minne
- [29.07.2009] Kjører en million Linux-kjerner på samme system
- [24.06.2009] IBM utvikler vannavkjølte bladservere
- [10.03.2009] IBM vil bli dominerende igjen
- [23.12.2008] Advarer mot storm av fiendlige dataangrep