
Kommentar: I dag vil verden skape 2,5 exabyte (2,5 x 1018 byte) med data. Gitt dagens vekstrate vil dette tallet nå 95,8 extabytes per dag innen 2020. Datamengden vokser så fort at 90 prosent av alle lagrede data i verden i dag har blitt skapt i løpet av de siste to årene.

Dette er data fra hundrevis av ulike kilder, inkludert eposter, dokumenter, apper, bilder, videoer, twittermeldinger, Facebook-poster og betalingstransaksjoner, for å nevne noen få. Dette blir kalt «big data». Men deres form – høy hastighet, høyt volum og høy variasjon – gjør «big data» svært vanskelig å tolke.


For investorer ligger pengene i smart analyse. Akkurat som Google utviklet den beste algoritmen for søk på nettet, vil noen, ett eller annet sted, utvikle den dominerende algoritmen for å analysere disse enorme datamengdene og konvertere zettabyte av ustrukturert «støy» til «business intelligence». Tradisjonelle metoder for å analysere data er ikke egnet til å takle digital informasjon produsert i denne skalaen. Jakten på en ny databaseteknologi som kan tolke og analysere enorme datamengder raskt og effektivt, er i gang.
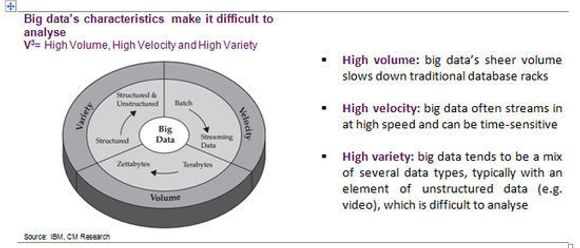
Store data – det neste store problemet
Da Google presenterte sin vellykket søkealgoritme for over ti år siden, endret det hele søkeindustrien og sikret et tiår med ekstrem profitt for selskapet. I dag er det en overflod av data på webben. Dette kommer fra web-crawlere, web-roboter, blogger, GPS-spor, trafikk-sensorer og mye, mye mer. Alle disse dataene kan, dersom den er riktig tolket, bli brukt defensivt til å forhindre kriminalitet, svindel, terrorisme og så videre. Men den kan også bli brukt kommersielt for å hente ut beslutningsstøtte (business intelligence) eller målrette markedsføring. Det er altså verdifullt både for styresmakter, og for private bedrifter som banker, markedsførere, butikkjeder og så videre.
Men problemet er at informasjonen er så kompleks at den ikke lar seg prosessere på konvensjonelle måter. Selskapene som kommer opp med løsningen på dette problemet, vil starte opphavet til en ny og svært verdifull industri. Og ettersom dette er en meget kompleks oppgave, vil de første aktørene kunne ta og beholde en dominerende posisjon over lang tid før nye aktører kan entre markedet.
Det er grunnen til at verdens største teknologiselskaper, fra Amazon, Google og Facebook til IBM, Cisco og Oracle til China Telecom, Verizon og Vodafone, investerer tungt i forskning på dette feltet.
Ettersom industrien på dette området utvikler seg ser vi fire trender materialiseres.
For det første: data flytter seg fra strukturerte til ustrukturerte formater, noe som øker kostnaden til analyse. Dette skaper et svært lukrativt marked for søkemotorer som kan tolke disse ustrukturerte dataene. For det andre: Proprietære databasestandarder må vike plassen for store, åpne teknologiplattformer basert på fri programvare. Hadoop er et eksempel på det. Dette betyr at barrierene for å entre markedet vil være lave for noe tid. For det tredje: mange selskaper velger å bruke nettsky-tjenester når de skal tolke store datamengder, fremfor å bygge egne datavarehus selv. For det fjerde: I fremtiden vil en økende andel av dataene bli generert fra kommunikasjon «maskin til maskin» ved bruk av sensorer. Disse dataene, som for stor grad er forretningskritisk og tidssensitiv, kan gi teleoperatører en ny måte å tjene på veksten av data.
Verdikjeden for «big data» industrien kan splittes i tre underkategorier:
Dataproduksjon: Rådata er samlet inn fra flere kilder i stor skala.
Styring: Rådataene blir «renset», filtrert og analysert for å øke datakvaliteten
Konsumert: Dataene blir brukt kommersielt som «business intelligence»
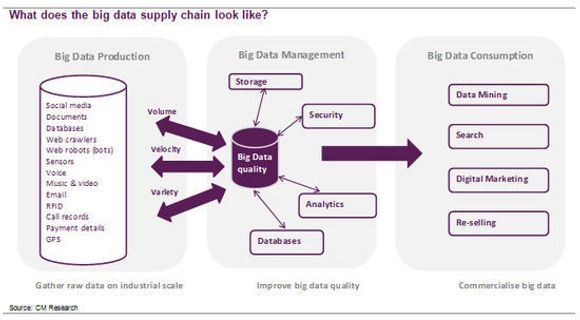
De store pengene ligger i å utvikle en analytisk motor som på en intelligent måte kan tolke store datamengder. Autonomy var et stort britisk programvareselskap som var det nærmeste vi kom et rendyrket og frittstående selskap innen denne industrien. I fjor ble det kjøpt opp av Hewlett Packard. Gitt at de mest vellykkede «business intelligence»-selskapene er hjemmehørende i USA, er det også gode odds for at morgendagens analysemotor for store data vil bli utviklet nettopp i Amerika. Men gitt alle de kulturelle og språklige barrierene på tvers av webben, som spiller en viktig rolle i tolkningen av store datamengder, er det også en mulighet at en kinesisk eller indisk motor vil vokse frem samtidig.
Ettersom den digitale tidsalder girer opp, vil etterspørselen etter analyseverktøy øke: Myndigheters etterretningsorganisasjoner vil etterspørre bedre verktøy for å gå gjennom overvåkningsinformasjon for å bekjempe terrorisme, kriminalitet og kyberkrigføring. Selskaper vil betale for «business intelligence»-programvare for å skaffe seg et konkurransemessig fortrinn.
Hvem vil vinne?
De dominerende databaseselskapene, som IBM og Oracle, investerer milliarder i å utvikle analysemotorer. Men en rekke nestegenerasjons databaseplattformer – som nevnte Hadoop – er basert på åpen kildekode og muliggjør at nye aktører (som Cloudera) kan entre markedet uten å gjøre voldsomme investeringer.
Samtidig er det en rekke internettselskaper, fra Amazon til kinesiske Baidu, ikke hatt tid til å vente på IT-industrien, så de har utviklet sine egne databaser for å håndtere de enorme datamengdene som går gjennom deres systemer. Google og Facebook har allerede sofistikerte «black box» som er kapable til å håndtere store datamengder. Men selv de sliter med å kommersialisere rike og ustrukturerte data, som for eksempel video.
Alle disse dataene må imidlertid lagres et sted, så lagringsselskaper som EMC, Dell, HP og NetApp vil tjene på utviklingen. Det samme vil nettverks-leverandører som Brocade, SGI og Cisco. Dessuten må informasjon bli tilgjengelig for selskapene, noe Citrix Systems, Red Hat, Salesforce.com og VMware vil fortsette å vokse på.


Sikkerhet er også et viktig tema, så nisjespillere, som Check Point Software, vil spille en lønnsom rolle, og mye av informasjonen trenger å gå sikkert, stabilt og raskt fra maskin til maskin. Det er her telekom-operatørene, som AT&T, China Telecom og Vodafone, er godt posisjonert til å gjøre store gevinster, selv om myndighetene kan komme til å ta deler av dette.
Også IT-konsulenter som Accenture, Infosys og Tata Consulting Service vil tjene. De vil få et nytt produkt å selge, selv om spesialister som Informatica vil kunne ta en stor del av markedet. Datasenter-aktører, som Rackspace og Telecity, vil tjene på utviklingen.
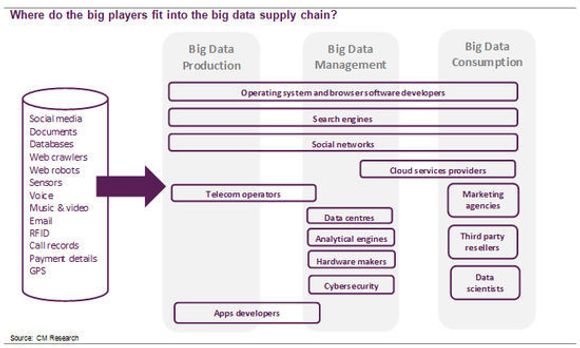
Som grafen over viser, er det en rekke teknologi, media og telekom-aktører som i dag er inne i verdikjeden skapt av store datamengder. Det som er interessant, er at de store nettselskapene som Facebook og Google strekker seg over hele verdikjeden: De henter inn data via sine sosiale medieplattformer, nettlesere og operativsystem. Dette prosesserer de selv ved å bruke sine egenutviklede databasesystemer, og de bruker dataene til å målrette markedsføringskroner til kunder som er mest troende til å respondere på reklamen raskt.
De kontrollerer dataene og hvordan de brukes.
Mens mange teknologianalytikere peker på IBM og Oracle som de to «Big Data-mestrene», så bør investorer som vil tjene penger på denne trenden holde øye med aktører som Amazon, Baidu, Google, Facebook og Twitter. Deres analysemotorer er godt gjemt – men er egnet til å «røske opp» i markedet.
Den London-basert investeringsanalytikeren Cyrus Mewawalla i CM Research skriver faste kommentarer for digi.no. Han har 20 års erfaring fra teknologi-, medie- og telekomsektoren som analytiker og konsulent. Mewawalla rådgir institusjonelle investorer om investeringstrender innen denne sektoren og er anerkjent for å avdekke trender tidlig.
Les også:
- [25.05.2012] Hva er Facebook egentlig verdt?
- [23.03.2012] Mobil lommebok: App eller NFC?
- [24.02.2012] – Google kan vente seg en smell
- [03.02.2012] Kina leder an i sosiale medier
- [06.01.2012] De 10 viktige temaene i 2012






