
Verden blir stadig mer datadrevet. Å være datadrevet vil si at man tar beslutninger på grunnlag av data, ikke intuisjon. Dette er et problem for mange ledere, siden de er vant til å bestemme basert på hva de tror og ikke hva fakta (eller i alle fall data) sier. Men det kan gi betydelige økonomiske resultater - Finn.no, for eksempel, har en datadrevet ledelses- og beslutningsprosess som leverer 1000 oppdateringer i uken og en EBITDA på 37%, år etter år.
Men hvilke beslutninger gjenstår for en ledelse i en bedrift der det er dataene, eksperimentene, og modellene som bestemmer?
Svaret er at de i hovedsak skal bestemme kriteriene for hvordan modeller og data skal brukes.

Ny Gemini-modell skal være den beste på markedet
Her er et eksempel fra en medisinsk virkelighet: Sett at vi vil bruke en maskinlæringsmodell for å avgjøre om en føflekk inneholder kreftceller eller ikke. Vi har masse registrerte observasjoner av føflekker (lengde, bredde, farge, regularitet, form) og andre data om pasientene fra tidligere undersøkelser, og vi vet også for disse observasjonene om det faktisk var kreft eller ikke. Vi tar disse dataene, gir dem til en dataanalytiker og ber vedkommende lage en modell, eller en algoritme om du vil. Analytikeren programmerer i vei og kommer frem til en modell som gjetter riktig i 90% av tilfellene.
Over til ledelsen: Er denne modellen bra nok, og skal den tas i bruk?
I utgangspunktet virker det enkelt - hvis modellen er bedre enn det som gjøres nå, er det jo bare å ta den i bruk? Hvis en lege som undersøker en pasient finner riktig diagnose i bare 80% av tilfellene, er det jo enkelt: Da bruker man algoritmen. Dette at enkle algoritmer ofte er mer korrekte enn ekspertvurderinger er en kjent sak - det er årsaken til at vurderingen om ditt nyfødte barn skal i kuvøse eller ikke blir tatt basert på en enkelt poengsystem (APGAR) som hvem som helst kan bruke i stedet for at en fødselslege eller sykepleier tar en titt på barnet og sier hva de synes.
Men ting er mer komplisert enn som så. Alle modeller gjør feil, men hva slags feil gjør de? Det man må gjøre, er å lage det som på engelsk heter en confusion matrix (og som ikke har noen norsk navn, men hvorfor ikke “forvirringsmatrise”). En forvirringsmatrise sammenligner virkelighet og modellprediksjon, og kan f.eks. se slik ut:
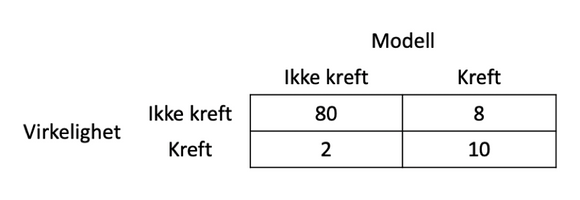
Denne matrisen viser en modell som er 90% korrekt - den har funnet 80 tilfeller som ikke var kreft, og 10 som var det. Men den har tatt feil i ti av tilfellene: To der det var kreft men den predikerte ikke-kreft (falsk negativ), åtte der den trodde det var kreft men det ikke var det.
Hvis en lege har 80% feilrate, ser det jo ut til at denne modellen er bedre. Bare å ta den i bruk.
Men… feil er ikke feil. Det er opplagt mye mindre alvorlig med en falsk positiv (at man tror en pasient har kreft, men tar feil) enn en falsk negativ (det er kreft, men man finner det ikke). I det første tilfellet får pasienten operert ut en føflekk som viste seg å være ufarlig, i det siste kan man ende opp med spredning og en alvorlig sykdom.
Men maskinlæringsalgoritmer kan endres. Sett at man finner en annen modell (eller endrer litt på den man har, for eksempel ved å sette lavere kriterier for å vurdere noe som kreft) og får en modell som ser slik ut:
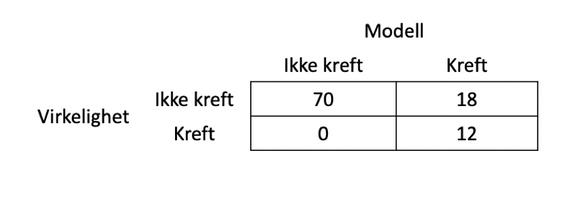
Denne modellen har en treffsikkerhet på 82% - dårligere enn den første modellen - men den finner alle krefttilfellene. Antakelig er dette en mye bedre modell å bruke enn den første.
Skal man kunne velge en riktig modell, må man ha kunnskaper om konsekvenser - både hva modellen skal måles opp mot, men også om hva konsekvensene vil være om modellen tar feil (noe den helt sikkert gjør.) Det vil kreve at man tar en beslutning om forholdet mellom typer feil - en prislapp, om du vil. Faktisk må man sette en pris for hele modellen - hva koster den (eller sparer den) når den gjør noe riktig, og hva koster den når den tar feil.

Open AIs kraftigste modell peker ut hvilke jobber den vil erstatte
Å finne modeller som fungerer er en jobb for spesialister og teknologer - i dette tilfellet dataanalytikere. Å sette verdi på konsekvenser er et lederansvar man ikke kan løpe fra - og en forutsetning for å skape den data-drevne bedriften.







