Denne artikkelen er levert av Titan.uio.no
Det dreier seg om språkteknologi – samme type teknologi som ligger i bunn når du søker på nett eller bruker oversetterverktøy som Google Translate.
– Målet vårt er å utvikle teknologi som analyserer norske tekster. Det finnes slik teknologi for engelsk og andre store språk, men så langt har det vært lite av det på norsk. Og der må vi gjøre jobben selv, vi kan ikke regne med at de store IT-gigantene hjelper for mye, sier forsker Lilja Øvrelid.
Hun er en av UiO-forskerne som i et halvt års tid har samarbeidet med Schibsted, NRK og Aller Media om dette.
Analyserte 35 000 anmeldelser
Så langt har arbeidet ført frem til datasettet NoReC (Norwegian Review Corpus) som omfatter over 35 000 anmeldelser fra de norske nyhetsmediene, hver av dem er rangert med et terningkast.
Hver anmeldelse inneholder også en rekke metadata, blant annet tematisk kategorisering og forfatter av teksten.
Prosjektet har delvis vært finansiert av Forskningsrådets IKTPLUSS-ordning. Og nylig fikk prosjektet fornyet støtte - med ytterligere tre år.
Nå vil forskerne bygge videre på NoReC - gå mer i dybden.
Dette prosjektet har fått navnet SANT (Sentiment Analysis for Norwegian Text), og ledes av Øvrelid og kollega Erik Velldal.
%25201%2520(2)%2520(1).png)
(Artikkelen fortsetter under)

Terningkast og «treningsdata»
SANT handler blant annet om å fremskaffe data for å utvikle maskinlæringsalgoritmer, som lærer å klassifisere tekster som positive, nøytrale eller negative.
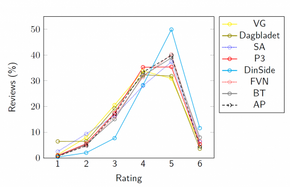
Mye av vurderingene og kritikken innen film, litteratur, musikk og annen kunst, samt dataspill restauranter, kameraer og andre forbrukerprodukter skjer ved terningkast – det vil si på en skala fra 1 til 6.
Forskerne klassifiserer anmelderens ord og uttrykk som positive, nøytrale eller negative.
Og ved å sammenholde selve anmeldelsesteksten med terningkastene kan man trene og evaluere maskinlærte modeller.


– Ved hjelp av terningkastene kan vi utvikle modeller som automatisk kan tildele terningkast til nye tekster, utdyper Øvrelid.
SANT-prosjektet har som mål å utvikle teknologi for norsk, men vil ikke løse alle utfordringer knyttet til dette området.
Finkornet analyse
– Ofte ønsker man å gjøre mer finkornet analyse av tekster, for eksempel identifisere hva som er gjenstand for positive eller negative holdninger og hvem som innehar holdningene, sier Øvrelid.

Da må mer komplisert teknologi innen kunstig intelligens tas i bruk – blant annet utvikling av fler-lags kunstige nevrale nettverk, også kalt dyp læring.
Slike dype metoder har kommet for fullt innenfor hele maskinlæringsfeltet de siste årene og dette er en kompetanse som det er stor etterspørsel etter.
– Vi vil bygge opp bedre kompetanse på dyp læring. Det er krevende forskning, men vi har en lang vei å gå. For eksempel kan slike ting som sarkasme være vanskelig å oppdage i en tekst og ikke minst ironi – hvor for eksempel en setning som isolert sett kan se ut om den er positiv, men likevel er negativ når man ser hele konteksten og har kunnskap om skribenten.
Diskusjonsfora og sosiale medier
Øvrelid forteller at det er veldig stor interesse for prosjektet. Forskerne er kontaktet av en rekke aktører innen næringsliv og akademia.
– Teknologien er veldig anvendelig. Den kan brukes til å se hva som rører seg i folket og stemninger i debatter, sier Øvrelid som påpeker at teknologien de utvikler er basert på åpen kildekode og kan derfor gjenbrukes av andre.
På lengre sikt kan det bli aktuelt å analysere tekster i ulike diskusjonsfora på nett og sosiale mediekanaler som Facebook, Twitter og Youtube. Øvrelid påpeker imidlertid at på dette feltet er reguleringen av databruken streng, av personvernhensyn – også for forskere.
Overvåking og samfunnsnytte
– Dette kan vel bidra til økt overvåkning i samfunnet?
– I likhet men mye annen teknologi kan også sentimentanalyse ha negative bruksområder, særlig ukritisk bruk på individnivå. Her er det viktig med regulering av datatilgang og bruk, som den nye personvernforordningen fra EU, sier Øvrelid som mener det også er viktig å øke bevisstheten rundt dette hos forbrukerne.
Samtidig påpeker hun at det finnes en rekke områder hvor denne typen dataanalyse kan være veldig samfunnsnyttig.
– For eksempel kan den brukes til automatisk å gjenkjenne hatytringer og trakassering. Det kan også bidra til mediedemokratisering, det vil si at man kan benytte teknologien til å analysere det norske medielandskapet og blant annet identifisere ensidig eller unyansert framstilling av personer eller nyhetssaker over tid.
Øvrelid trekker også fram et annet aktuelt område. I etterkant av Donald Trumps presidentkampanje ble det avslørt utstrakt bruk av såkalte bot'er, det vil si automatiske systemer i sosiale medier som er laget for å påvirke medieovervåking.
– Sentimentanalyse bidro i den senere identifiseringen av bot'ene, sier hun.